collections
Table of contents
- dataclasses > dataclass
- collections > namedtupe
- collections > defaultdict
- collections > Counter
- collections > OrderDict
dataclasses > dataclass
from dataclasses import dataclass
@dataclass
class AnimalClass :
name: str
habitat: str
teeth: int = 0
snowman = AnimalClass('yeti', 'Himalayas', 46)
duck = AnimalClass(habitat='lake', name='duck')
print(snowman) # AnimalClass(name='yeti', habitat='Himalayas', teeth=46)
AnimalClass(name='yeti', habitat='Himalayas', teeth=46)
print(duck) # AnimalClass(name='duck', habitat='lake', teeth=0)
AnimalClass(name='duck', habitat='lake', teeth=0)
collections > namedtupe
네임드 튜플의 특징을 정리하면 다음과 같다.
- 불변 객체처럼 행동한다.
- 객체보다 공간 효율성과 시간 효율성이 더 좋다.
- 딕셔너리 형식의 대괄호([ ])대신 온점(.)표기법으로 속성을 접근할 수 있다.
- 네임드 튜플을 딕셔너리의 키처럼 쓸 수 있다.
클래스 = collections.namedtuple(‘자료형이름’, [‘요소이름1’, ‘요소이름2’])
namedtuple로 생성한 클래스는 값을 넣어서 인스턴스를 만들 수 있으며
인스턴스.요소이름 또는 인스턴스[인덱스] 형식으로 요소에 접근할 수 있습니다.
- 인스턴스 = 클래스(값1, 값2)
- 인스턴스 = 클래스(요소이름1=값1, 요소이름2=값2)
- 인스턴스.요소이름1
- 인스턴스[인덱스]
from collections import namedtuple
Duck = namedtuple('Duck', 'bill tail')
duck = Duck('wide orange', 'long')
print(duck )
print(duck.bill)
parts = {'bill': 'wide orange', 'tail': 'long'}
duck2 = Duck(**parts)
print(duck2)
duck3 = duck2._replace(tail='magnificent', bill='crushing')
print(duck3)
import math
import collections
Point2D = collections.namedtuple('Point2D', ['x', 'y']) # namedtuple로 점 표현
p1 = Point2D(x=30, y=20) # 점1
p2 = Point2D(x=60, y=50) # 점2
a = p1.x - p2.x # 선 a의 길이
b = p1.y - p2.y # 선 b의 길이
c = math.sqrt((a * a) + (b * b))
print(c) # 42.42640687119285
collections > defaultdict
periodic_table = {'Hydrogen': 1, 'Helium': 2}
periodic_table.setdefault('Carbon', 12) # 키 미존재 시 추가
print(periodic_table) # {'Hydrogen': 1, 'Helium': 2, 'Carbon': 12}
periodic_table.setdefault('Carbon', 33) # 키 존재 시 미 변경
print(periodic_table) # {'Hydrogen': 1, 'Helium': 2, 'Carbon': 12}
from collections import defaultdict
periodic_table = defaultdict(int) # 정의 : defaultdict(함수명)
print(periodic_table) # defaultdict(<class 'int'>, {})
periodic_table['Hydrogen'] = 1
periodic_table['Lead']
print(periodic_table) # defaultdict(<class 'int'>, {'Hydrogen': 1, 'Lead': 0})
# 함수 정의하여 기본값 생성 - 주로 람다함수 이용
def no_idea():
return 'no_data'
dic = defaultdict(no_idea)
dic['A']=125
dic['B']=200
print(dic['C']) # no_data
food_counter = defaultdict(int)
for food in ['spam', 'spam', 'eggs', 'spam']:
food_counter[food] += 1
print(food_counter) # defaultdict(<class 'int'>, {'spam': 3, 'eggs': 1})
collections > Counter
# 항목 세기
from collections import Counter
breakfast = ['spam', 'spam', 'eggs', 'spam']
breakfast_counter = Counter(breakfast)
print(breakfast_counter) # Counter({'spam': 3, 'eggs': 1})
print(breakfast_counter.most_common()) # [('spam', 3), ('eggs', 1)] - 내림차순 정렬
print(breakfast_counter.most_common(1)) # [('spam', 3)] - 가장 많은 요소
# 리스트를 집합화하여 연산 가능
lunch = ['eggs', 'eggs', 'bacon']
lunch_counter = Counter(lunch)
print(lunch_counter) # Counter({'eggs': 2, 'bacon': 1})
result1 = breakfast_counter + lunch_counter # 뺄셈도 가능
print(result1) # Counter({'spam': 3, 'eggs': 3, 'bacon': 1})
result2 = breakfast_counter & lunch_counter
print(result2) # Counter({'eggs': 1})
collections > OrderDict
# dict 순서 유지 - 3.7이후 버전은 기본
from collections import OrderedDict
quotes = {
'Moe': 'A wise guy, huh?',
'Larry': 'Ow!',
'Curly': 'Nyuk nyuk!',
}
for stooge in quotes:
print (stooge)
quotes = OrderedDict([
('Moe', 'A wise guy, huh?'),
('Larry', 'Ow!'),
('Curly', 'Nyuk nyuk!'),
])
print(
quotes
) # OrderedDict([('Moe', 'A wise guy, huh?'), ('Larry', 'Ow!'), ('Curly', 'Nyuk nyuk!')])
for stooge in quotes:
print (stooge)
'''
Moe
Larry
Curly
'''
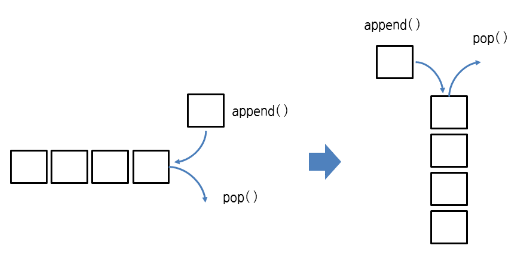
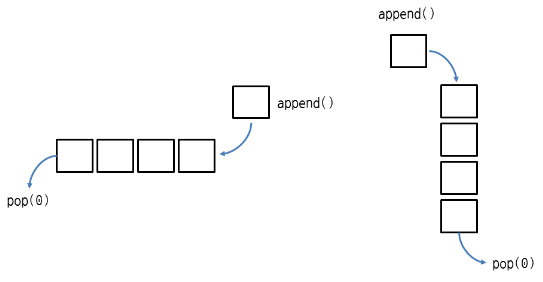
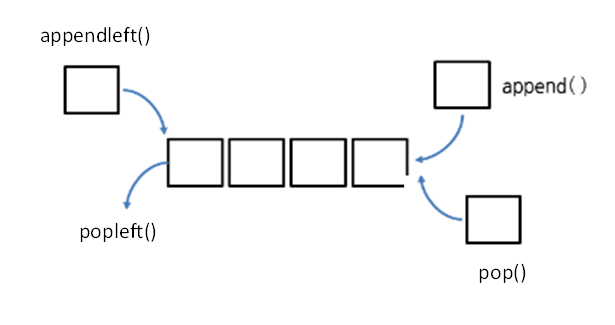
Stack + Queue == deque
append,pop는 덱의 오른쪽에 요소를 추가/삭제 appendleft, popleft는 덱의 왼쪽에 요소를 추가/삭제
from collections import deque # collections 모듈에서 deque를 가져옴
a = deque([10, 20, 30])
print(a) # deque([10, 20, 30])
a.append(500) # 덱의 오른쪽에 500 추가
print(a) # deque([10, 20, 30, 500])
a.popleft() # 덱의 왼쪽 요소 하나 삭제
print(a) # deque([20, 30, 500])
from collections import deque
def palindrome(word):
dq = deque(word)
while len(dq) > 1:
if dq.popleft() != dq.pop():
return False
return True
result = palindrome('a'), palindrome('racecar'),palindrome(''),palindrome('radar'),palindrome('halibut')
print(result) # (True, True, True, True, False)
def another_palindrome(word):
return word == word[::-1]
result = another_palindrome('radar'), another_palindrome('halibut')
print(result) # (True, False)