멀티프로세싱 1
Table of contents
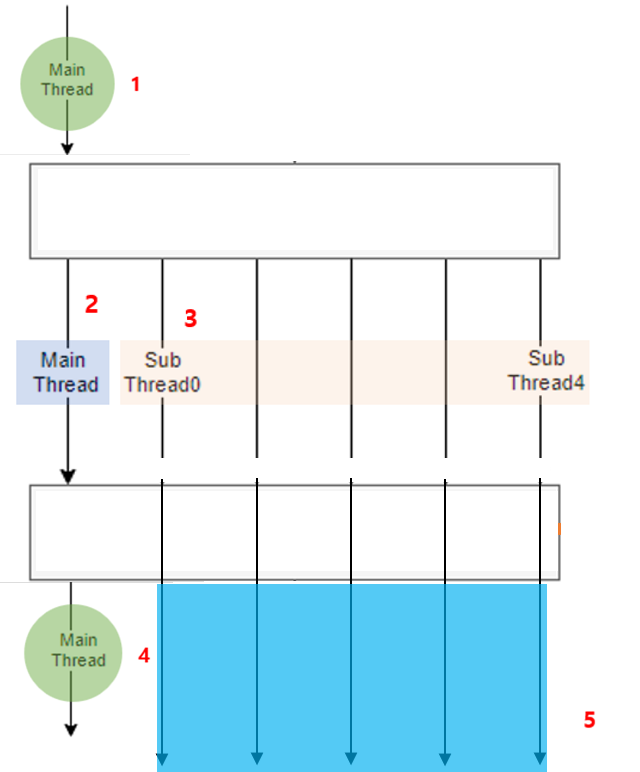
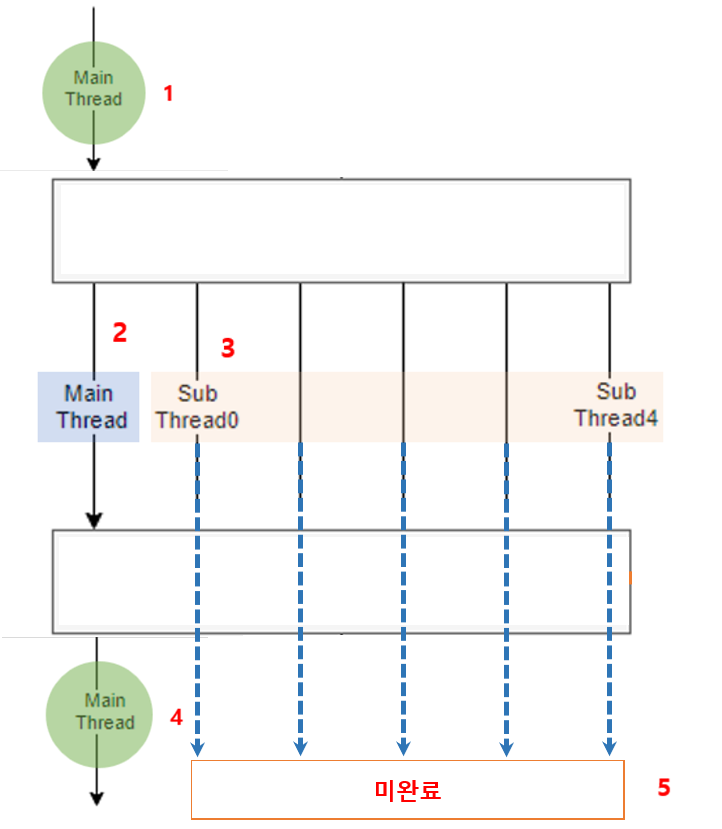
Thread
| 일반 | daemon | join |
|---|---|---|
 |  |  |
import threading
import time
class Worker(threading.Thread):
def __init__(self, name):
super().__init__()
self.name = name # thread 이름 지정
def run(self):
print("sub thread start ", threading.currentThread().getName())
time.sleep(3)
print("sub thread end ", threading.currentThread().getName())
print("main thread start")
for i in range(5):
name = "thread {}".format(i)
t = Worker(name) # sub thread 생성
t.start() # sub thread의 run 메서드를 호출
print("main thread end")
main thread start
sub thread start thread 0
sub thread start thread 1
sub thread start thread 2
sub thread start thread 3
sub thread start thread 4
main thread end
sub thread end thread 0
sub thread end thread 1
sub thread end sub thread end thread 2
thread 4
sub thread end thread 3
daemon True 설정
- 메인 스레드가 종료되면 서브스레드가 모두 종료
print("main thread start")
for i in range(5):
name = "thread {}".format(i)
t = Worker(name) # sub thread 생성
t.daemon = True # daemon 설정
t.start() # sub thread의 run 메서드를 호출
print("main thread end")
main thread start
SubProcess Start :thread 0
SubProcess Start :thread 1
SubProcess Start :thread 2
SubProcess Start :thread 3
SubProcess Start :thread 4
main thread end
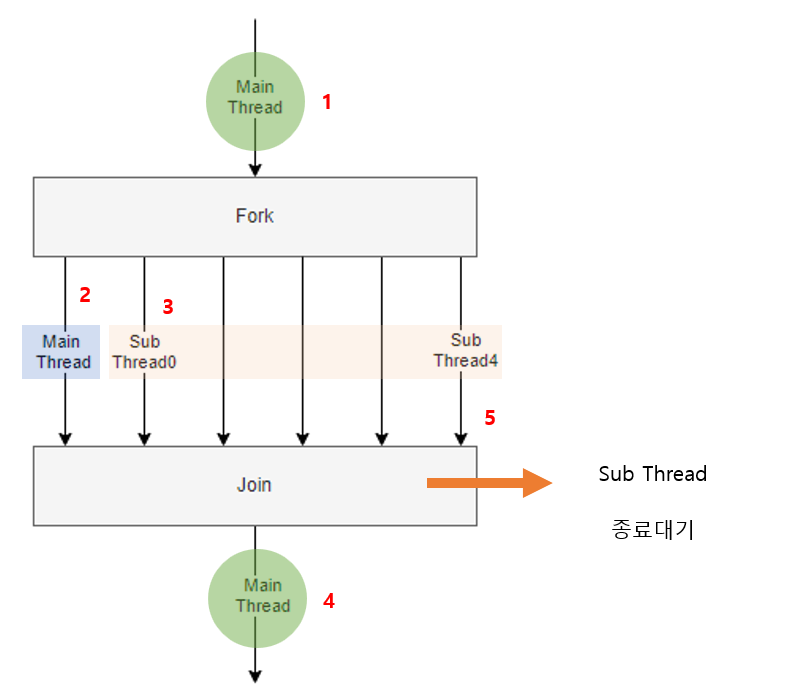
Fork와 Join
- fork : 메인 스레드가 서브 스레드를 생성하는 것을 의미
- join : 모든 스레드가 작업을 마칠 때까자 기다리는 것을 의미
보통 데이터를 여러 스레드를 통해서 병렬로 처리한 후 그 값들을 다시 모아서 순차적으로 처리해야할 필요가 있을 때 분할한 데이터가 모든 스레드에서 처리될 때까지 기다렸다가 메인 스레드가 다시 추후 작업을 하는 경우에 사용합니다.
import threading
import time
class Worker(threading.Thread):
def __init__(self, name):
super().__init__()
self.name = name # thread 이름 지정
def run(self):
print("sub thread start " + threading.currentThread().getName())
time.sleep(5)
print("sub thread end " + threading.currentThread().getName())
print("main thread start")
t1 = Worker("1") # sub thread 생성
t1.start() # sub thread의 run 메서드를 호출
t2 = Worker("2") # sub thread 생성
t2.start() # sub thread의 run 메서드를 호출
t1.join()
t2.join()
print("main thread end")
main thread start
sub thread start 1
sub thread start 2
sub thread end 2sub thread end 1
main thread end
반복문을 이용한 스레드 처리
import threading
import time
class Worker(threading.Thread):
def __init__(self, name):
super().__init__()
self.name = name # thread 이름 지정
def run(self):
print("sub thread start ", threading.currentThread().getName())
time.sleep(5)
print("sub thread end ", threading.currentThread().getName())
print("main thread start")
threads = []
for i in range(3):
thread = Worker(i)
thread.start() # sub thread의 run 메서드를 호출
threads.append(thread)
for thread in threads:
thread.join()
print("main thread post job")
print("main thread end")
MultiProcessing
현재 프로세서 정보 확인
import multiprocessing as mp
import time
p = mp.current_process()
print(p.name, p.pid) # 현재 프로세서의 이름, pid 확인
**sub process spawning
## 함수 매핑
import multiprocessing as mp
def worker():
print('sub processor 실행')
if __name__ == "__main__":
# sub processor 생성
p = mp.Process(name='SubProcessor1', target=worker)
p.start()
## class 매핑
import multiprocessing as mp
class Worker:
def __init__(self,value):
self.value = value
def run(self):
print('cur processor :',mp.current_process().name, '\nvalue :',self.value)
if __name__ == "__main__":
w = Worker(name:='work class')
p = mp.Process(name='Sub Processor', target=w.run)
p.start()
** 인수는 tuple로 전달
## 인수 전달 경우
인자 전달 (함수 버전)
import multiprocessing as mp
def work(value):
pname = mp.current_process().name
print(pname, value)
if __name__ == "__main__":
p = mp.Process(name="Sub Process", target=work, args=("hello",))
p.start()
p.join()
print("Main Process")
daemon, join 설정 가능
if __name__ == "__main__":
w = Worker(name:='work class')
p = mp.Process(name='Sub Processor', target=w.run)
p.daemon = True # 서브프로세서 생성시 daemon 인자로 설정 가능
p.start()
p.join() # join 설정
프로세서 상태확인 및 프로세서 죽이기
import multiprocessing as mp
import time
def work():
while True:
print("sub process is running")
time.sleep(1)
if __name__ == "__main__":
p = mp.Process(target=work, name="SubProcess")
print("Status: ", p.is_alive())
p.start()
print("Status: ", p.is_alive())
time.sleep(5) # 메인 프로세스 5초 대기
p.kill() # 서브 프로세스 종료
print("Status: ", p.is_alive()) ## join 때문에 alive 생태
p.join() # 메인 프로세스는 서브 프로세스가 종료될 때까지 블록됨
print("Status: ", p.is_alive())
Pool
- sub processor pool 생성 -> 여러 프로세서 생성
from multiprocessing import Pool
def worker(name):
print(name)
if __name__ == "__main__":
# Pool 생성
p = Pool(2) # Pool 생성
p.map(worker,range(100)) # mapping
멀티프로세스와 큐(Queue)
프로세스내의 스레드는 한 프로세스에 할당된 자원을 공유(스레드간 자원 공유)하지만 프로세스와 프로세스는 자원을 공유하지 않습니다. 따라서 프로세스와 프로세스 사이에서 자원을 전달하려면 특별한 통신이 필요합니다.
보통 프로세스 사이의 자원 공유를 위해 큐(Queue)라는 자료구조를 사용합니다.

import multiprocessing as mp
q = mp.Queue()
q.put(1)
q.put(2)
q.put(3)
data1 = q.get()
data2 = q.get()
data3 = q.get()
print(data1)
print(data2)
print(data3)
멀티프로세싱과 PyQt
GUI를 구성하는 경우 특정 함수나 메소드에서 오랫동안 작업을 수행하게되면 GUI가 멈추는 현상이 발생합니다.
이런 경우에는 작업 시간이 오래 걸리는 메소드를 처리하기 위해 별도의 스레드를 생성하는 것이 좋습니다.
- 작업이 I/O 위주의 작업이라면 멀티 스레드 사용
- 계산 위주의 작업이라면 멀티 프로세스 사용
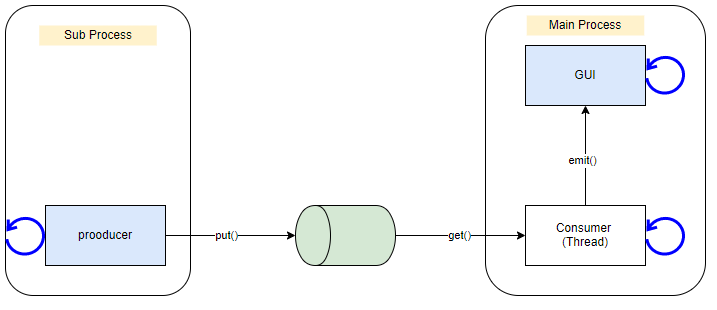
사용된 프로세스는 Main Process와 생산자를 위해 생성한 Sub Process 두 개입니다.
Main Process는 다시 GUI를 위한 스레드와 Consumer를 위한 스레드가 있습니다.producer는 어떤 데이터를 생상하는 역할
증권사로부터 데이터를 가져오는 프로세스일 수도 있고 웹에서 데이터를 가져오는 프로세스일 수 있습니다. 중요한 점은 이 프로세스의 역할이 데이터를 생산한다는 것입니다. 데이터를 생산하는 역할을 맞은 Producer는 데이터가 생성되면 큐에 넣어주기만 합니다.생산자의 반대 역할이 바로
소비자(Consumer)입니다. 소비자는 큐만 쳐다보고 있다가 큐에 데이터가 입력되면 데이터를 큐에서 빼옵니다. 그리고 큐에서 빼온 데이터를 PyQt와 같은 GUI 담당 스레드에게 전달해줍니다. 소비자 역시 언제 생산자가 데이터를 큐에 넣어줄 지 모르기 때문에 계속해서 큐를 쳐다보고 있어야 합니다. 그래서 GUI와 달리 별도의 스레드로 구성합니다.
import sys
from PyQt5.QtWidgets import *
from PyQt5.QtCore import *
from multiprocessing import Process, Queue
import multiprocessing as mp
import datetime
import time
def producer(q):
proc = mp.current_process()
print(proc.name)
while True:
now = datetime.datetime.now()
data = str(now)
q.put(data)
time.sleep(1)
class Consumer(QThread):
poped = pyqtSignal(str)
def __init__(self, q):
super().__init__()
self.q = q
def run(self):
while True:
if not self.q.empty():
data = q.get()
self.poped.emit(data)
class MyWindow(QMainWindow):
def __init__(self, q):
super().__init__()
self.setGeometry(200, 200, 300, 200)
# thread for data consumer
self.consumer = Consumer(q)
self.consumer.poped.connect(self.print_data)
self.consumer.start()
@pyqtSlot(str)
def print_data(self, data):
self.statusBar().showMessage(data)
if __name__ == "__main__":
q = Queue()
# producer process
p = Process(name="producer", target=producer, args=(q, ), daemon=True)
p.start()
# Main process
app = QApplication(sys.argv)
mywindow = MyWindow(q)
mywindow.show()
app.exec_()
멀티프로세싱과 클래스 Process의 target 파라미터로 Woker 클래스 객체의 run 함수를 전달합니다.
이 경우 Worker 클래스 자체는 MainProcess에서 생성된 것이며 생성자에서 프로세스 이름을 출력하면 MainProces로 출력됩니다.
이와달리 run 함수는 SubProcess로 출력됩니다.
한가지 주의할 점은 클래스 내부의 변수를 읽는 동작입니다. 이런 동작은 다른 프로세스에 있는 값을 읽는 것인데 한 프로세스에서 다른 프로세스의 값을 직접 읽을 수 없음에 유의해야합니다.
import multiprocessing as mp
class Worker:
def __init__(self):
print("__init__", mp.current_process().name)
self.name = None
def run(self, name):
self.name = name
print("run", self.name)
print("run", mp.current_process().name)
if __name__ == "__main__":
w = Worker()
p = mp.Process(target=w.run, name="SubProcess", args=("bob",))
p.start() # target function is called
p.join()
# 서브 프로세스는 종료된 상태
# 생성자는 메인 프로세스이므로 self.name은 None
print(w.name)
__init__ MainProcess
run bob
run SubProcess
None
import multiprocessing as mp
class Worker:
def __init__(self):
print("__init__", mp.current_process().name)
self.name = None
def run(self, name):
self.name = name
print("run", self.name)
print("run", mp.current_process().name)
if __name__ == "__main__":
w = Worker()
p = mp.Process(target=w.run, name="SubProcess", args=("bob",))
p.start() # target function is called
print("before join")
print('SubProcess: ', p.is_alive())
print(w.name)
print("---------------------------")
p.join()
print('---------------------------')
print("after join")
print('SubProcess: ', p.is_alive())
print(w.name)
타켓으로 클래스 전달
이번에는 target 파라미터로 클래스 이름을 전달해봅시다. 이 경우 start 함수가 호출될 때 해당 클래스의 생성자가 호출됩니다. 생성자에서 프로세스 이름을 출력하면 이번에는 SubProcess가 됩니다.
import multiprocessing as mp
class Worker:
def __init__(self, name):
print("__init__", mp.current_process().name)
self.name = name
self.run()
def run(self):
print("run", self.name)
print("run", mp.current_process().name)
if __name__ == "__main__":
p = mp.Process(target=Worker, name="SubProcess", args=("bob",))
p.start() # __init__ is called
p.join()
__init__ SubProcess
run bob
run SubProcess
current.futures
from concurrent import futures
import math
import sys
def calc(val):
result = math.sqrt(float(val))
return val, result
def use_threads(num, values):
with futures.ThreadPoolExecutor(num) as tex:
tasks = [tex.submit(calc, value) for value in values]
for f in futures.as_completed(tasks):
yield f.result()
def use_processes(num, values):
with futures.ProcessPoolExecutor(num) as pex:
tasks = [pex.submit(calc, value) for value in values]
for f in futures.as_completed(tasks):
yield f.result()
def main(workers, values):
print(f"Using {workers} workers for {len(values)} values")
print("Using threads:")
for val, result in use_threads(workers, values):
print(f'{val} {result:.4f}')
print("Using processes:")
for val, result in use_processes(workers, values):
print(f'{val} {result:.4f}')
if __name__ == '__main__':
workers = 3
if len(sys.argv) > 1:
workers = int(sys.argv[1])
values = list(range(1, 6)) # 1 .. 5
main(workers, values)
Our use_threads() and use_processes() functions are now generator functions that call yield to return on each iteration. From one run on my machine, you can see how the workers don’t always finish 1 through 5 in order:
$ python cf2.py 5
Using 5 workers for 5 values
Using threads:
3 1.7321
1 1.0000
2 1.4142
4 2.0000
5 2.2361
Using processes:
1 1.0000
2 1.4142
3 1.7321
4 2.0000
5 2.2361